
Beyond Text-to-SQL: Combining Semantic Search and Structured Evidence
A practical walkthrough of hybrid retrieval over OpenAlex publications

In the previous post I described the architectural idea behind combining SQL and semantic search inside a data agent.
The main point was simple:
Semantic search should help the agent find candidate rows.
SQL should still be responsible for grounding, joining, filtering and returning the final evidence.
That post was mostly about the design pattern.
This one is about a concrete example.
I want to show what actually happens when a user asks a natural language question that cannot be solved well with plain SQL alone, but also should not be answered directly from a vector index.
The goal is not to show that the agent can generate a clever SQL query.
That would miss the point.
The interesting part is that the question mixes two different kinds of intent:
A semantic intent: find publications about a concept.
Structured constraints: restrict the search by language and publication year.
That is exactly the kind of case where hybrid SQL + semantic search becomes useful.
The example question
The user asks:
Using the OpenAlex database, find English-language publications related to natural language interfaces for databases, from 2016 onwards. Show 10 distinct publications with title, publication year, source name, citation count, and semantic score.
At first sight this looks simple.
But there is quite a lot happening inside that sentence.
The user is not asking for publications whose title contains the exact words:
natural language interfaces for databases
They are asking for publications that are semantically related to that topic.
At the same time, they are not asking for any publication in any language and any year. They want:
English-language publications
from 2016 onwards
And they want structured output:
title
publication year
source name
citation count
semantic score
That means the agent has to combine semantic retrieval with structured database grounding.
This is the kind of query I wanted to test.
Why this query?
I selected this query because it exercises several important parts of the architecture at the same time.
It is not just a Text-to-SQL benchmark question.
A pure SQL agent could try something like this:
WHERE LOWER(title) LIKE '%natural language interfaces for databases%'But that would be too brittle.
It might miss papers about:
natural language database querying
NLIDB
question answering over databases
database query formulation
natural language query interfaces
On the other hand, a pure semantic search system could return documents that are conceptually close, but it would have no strong reason to respect structured constraints such as publication year, language, source metadata or final database joins.
So this query is useful because it forces the agent to do three things:
Understand that semantic search is needed.
Ground natural language filters into real database values.
Use SQL to retrieve final structured evidence from the source tables.
That is the behavior I want from a data assistant.
Not just “generate SQL”.
Not just “search embeddings”.
But orchestrate both.
Why OpenAlex?
For this experiment I used OpenAlex.
OpenAlex is an open catalog of scholarly works, authors, institutions, venues, concepts and related academic metadata. It is useful for this kind of test because it contains both structured and semi-structured information:
publication titles
abstracts or searchable text
publication years
languages
source names
citation counts
identifiers
relationships between works and other academic entities
That makes it a good dataset for hybrid SQL + semantic search.
If the database only had clean numeric columns, SQL would be enough.
If the database only had unstructured text, a vector search demo would be enough.
OpenAlex sits in the middle. It has enough structure to require SQL, and enough text to make semantic search useful.
In this setup, the source database contains the canonical relational data, while a semantic projection is synchronized for retrieval.
A simplified view looks like this:
works
id
title
publication_year
language
source_name
cited_by_count
...
semantic_documents
document_id
search_text
language
publication_year
source_name
cited_by_count
embedding
...
The key point is that:
`semantic_documents.document_id` maps back to `works.id`
The semantic layer is not a second source of truth. It is a retrieval projection that helps the agent find candidate documents. The final answer still comes from the structured OpenAlex tables.
High-level flow
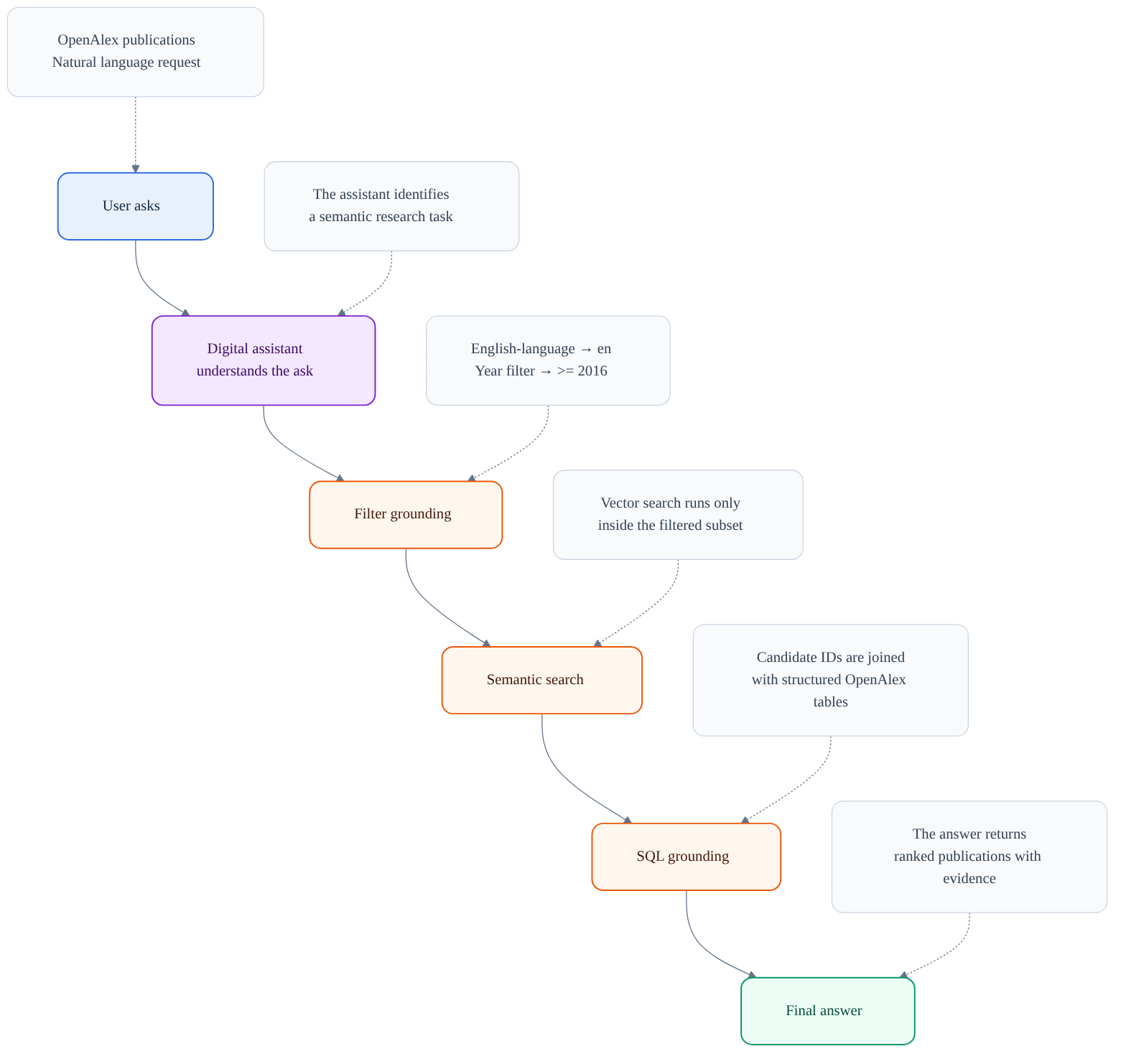
The high-level flow is:
User asks
→ Digital assistant understands the ask
→ Filter grounding
→ Semantic search
→ SQL grounding
→ Final answer
Each step has a clear responsibility.
The assistant first understands the task. Then it grounds the filters. Then it searches semantically, but only inside the filtered subset. Then it uses SQL to join the semantic candidates back to structured OpenAlex data. Finally, it composes a grounded answer.
Let’s walk through those steps.
Step 1: understanding the ask
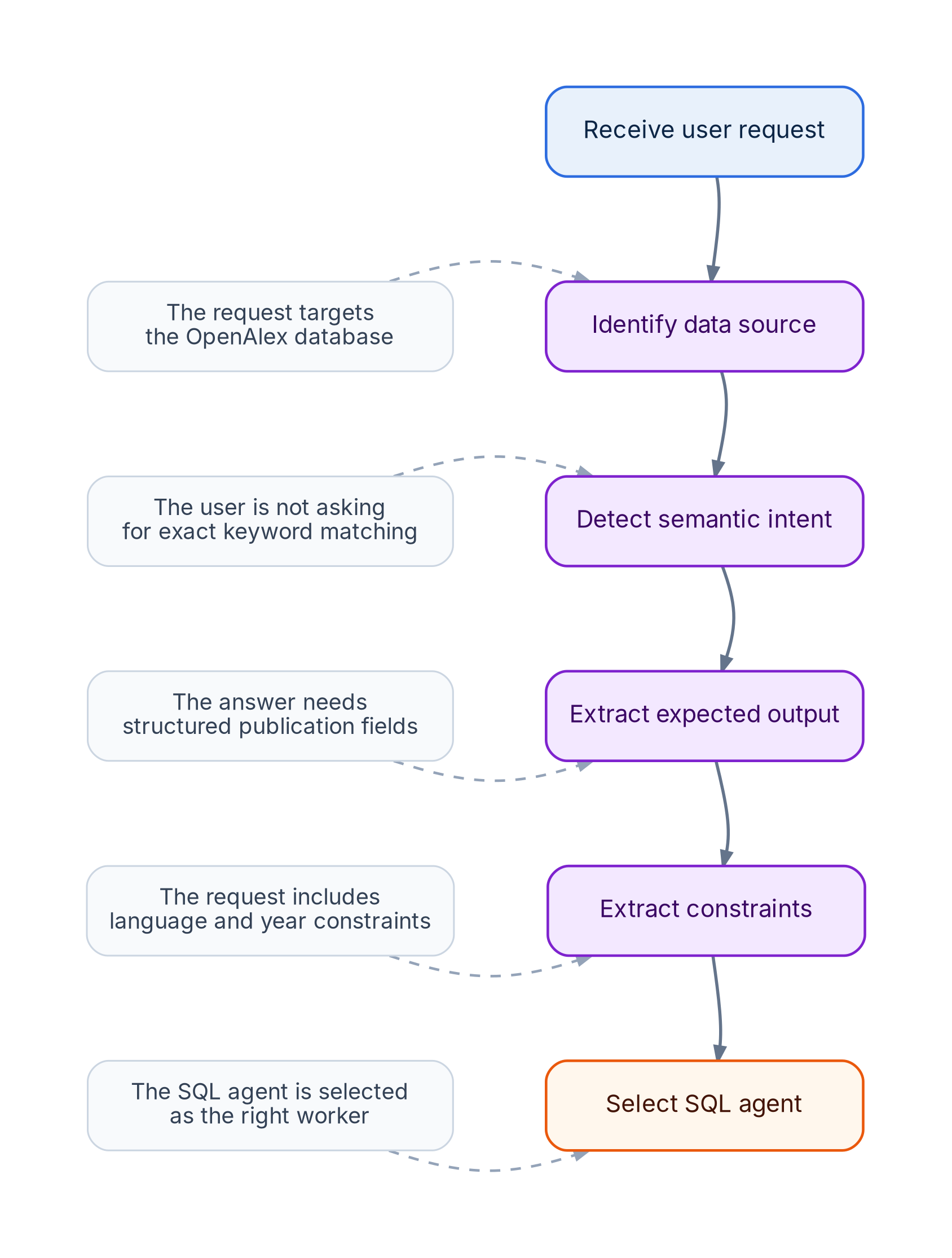
The first thing the assistant has to do is classify the request.
This is not a direct identifier lookup.
The user is not saying:
Show me publication W2950067395
The user is also not asking for a simple aggregate such as:
How many publications were published in 2019?
Instead, the user is asking for a ranked list of publications related to a topic.
That makes it a semantic research task over a SQL database.
A simplified structured interpretation of the request could look like this:
{
"data_source”: "openalex_duckdb",
"task_type”: "semantic_publication_search",
"semantic_query": "natural language interfaces for databases",
"expected_output": [
"title",
"publication_year",
"source_name",
"cited_by_count",
"semantic_score"
],
"constraints": {
"language”: "English",
"publication_year": {
"gte": 2016
}
},
"requires_semantic_search": true,
"requires_sql_grounding": true
}This structured representation is important because it separates the parts of the question.
The phrase:
natural language interfaces for databases
belongs to semantic search.
The phrase:
English-language
does not belong to semantic search. It is a metadata filter.
The phrase:
from 2016 onwards
is also a metadata filter.
And the requested fields belong to the SQL grounding step.
That separation is what allows the agent to avoid mixing everything into a single fragile SQL expression.
Step 2: filter grounding
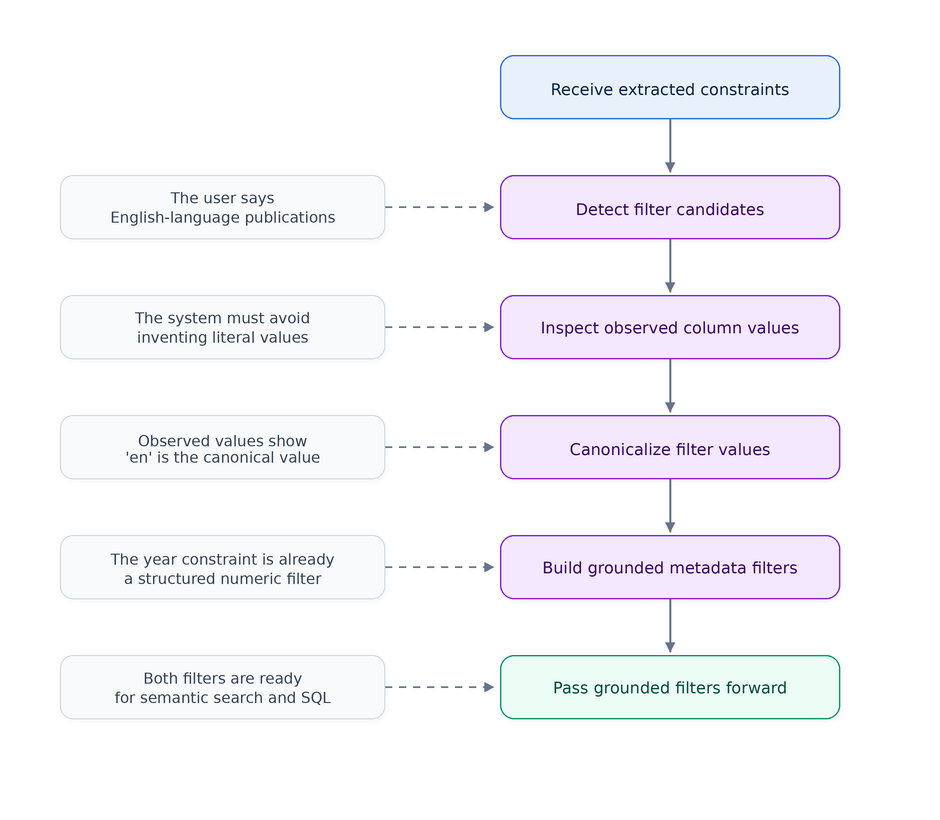
This was one of the most interesting parts of the example.
English-language publications
A naive agent might translate that directly into:
language = 'English'That looks reasonable from a natural language point of view.
But it may be wrong from a database point of view.
In the OpenAlex data, the canonical value for English is:
en
not:
English
This matters a lot.
If the agent sends the wrong filter into the semantic search layer, it may get zero candidates or, even worse, noisy candidates. And if it sends the wrong filter into SQL, the final query may return no rows even when relevant data exists.
So the agent needs to ground filter values before using them.
The corrected filter payload looks like this:
{
"original_constraints": {
"language": "English",
"publication_year": {
"gte": 2016
}
},
"grounded_filters": {
"language": "en",
"publication_year": {
"gte": 2016
}
},
"canonicalization": [
{
"field": "language",
"original_value": "English",
"canonical_value": "en",
"reason": "observed_standard_code_alias_dominates_literal",
"confidence": "high"
}
]
}This is a small detail, but it is a very important one.
The system should not invent literal database values from natural language. It should inspect or infer them from observed data when needed.
In this case, the agent learns that `en` is the correct database value for English-language publications.
The year filter is easier. It is already a numeric constraint:
{
"publication_year": {
"gte": 2016
}
}So the final grounded metadata filters are:
{
"language": "en",
"publication_year": {
"gte": 2016
}
}These filters are then passed both to semantic search and to SQL grounding.
That is the behavior we want.
Step 3: semantic search with metadata filters
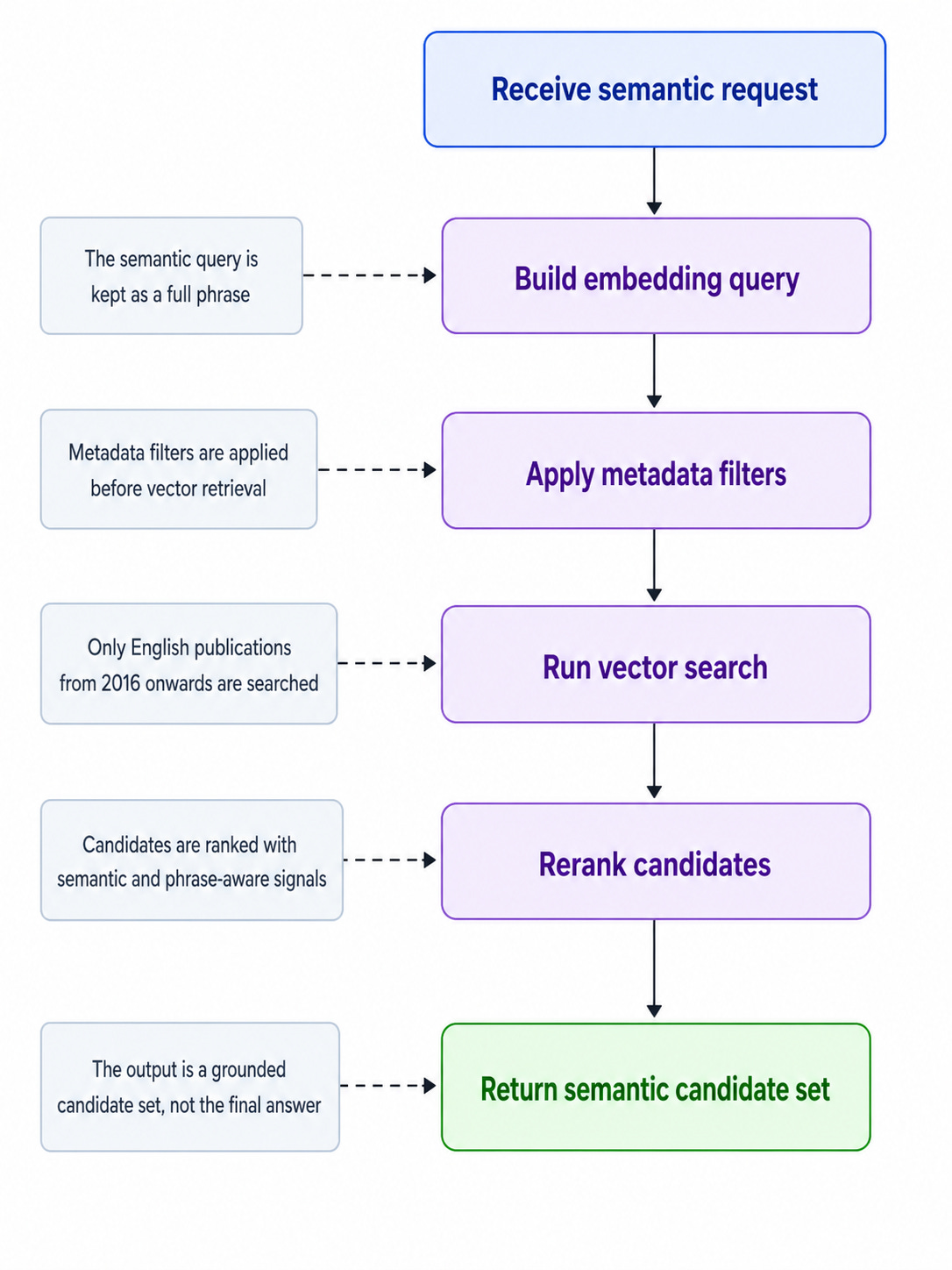
The next step is semantic search.
But the key point is this:
The semantic search should not run over the whole index and then let SQL filter the results afterwards.
That would introduce unnecessary noise.
If the user asked for English publications from 2016 onwards, the vector search should only rank documents inside that subset.
This is where metadata filtering matters.
The semantic search request can be represented like this:
{
"connection":"openalex_duckdb",
"semantic_query":"natural language interfaces for databases",
"source_table":"semantic_documents",
"metadata_filters":{
"language":"en",
"publication_year":{
"gte":2016
}
},
"top_k":10,
"ranking":{
"mode":"phrase_aware",
"signals":[
"semantic_score",
"lexical_score",
"phrase_score",
"ordered_proximity_score",
"technical_anchor_score"
]
}
}This is the important architectural difference.
The system is not doing this:
vector search over all publications
→ top-k candidates
→ SQL filters language and year afterwards
It is doing this:
filter semantic index by language and year
→ vector search inside the filtered subset
→ phrase-aware reranking
→ candidate document IDs
That means the vector search budget is spent on the relevant subset, not on the whole database.
A reduced semantic search output might look like this:
{
"retrieval_mode":"vector_with_metadata_filters",
"metadata_filters":{
"language":"en",
"publication_year":{
"gte":2016
}
},
"candidates":[
{
"document_id":"https://openalex.org/W2950067395",
"semantic_rank":1,
"semantic_score":0.895867,
"matched_phrases":[
"natural language",
"natural language interface",
"natural language interface database"
]
},
{
"document_id":"https://openalex.org/W2443450302",
"semantic_rank":2,
"semantic_score":0.669739,
"matched_terms":[
"database",
"interface",
"language"
]
},
{
"document_id":"https://openalex.org/W2922266198",
"semantic_rank":3,
"semantic_score":0.661938,
"matched_phrases":[
"natural language"
]
}
]
}At this point, the system has not answered the user yet.
It has only produced a grounded candidate set.
That distinction is essential.
Semantic search says:
These documents look relevant.
It does not say:
This is the final answer.
The final answer still needs SQL.
Step 4: SQL grounding
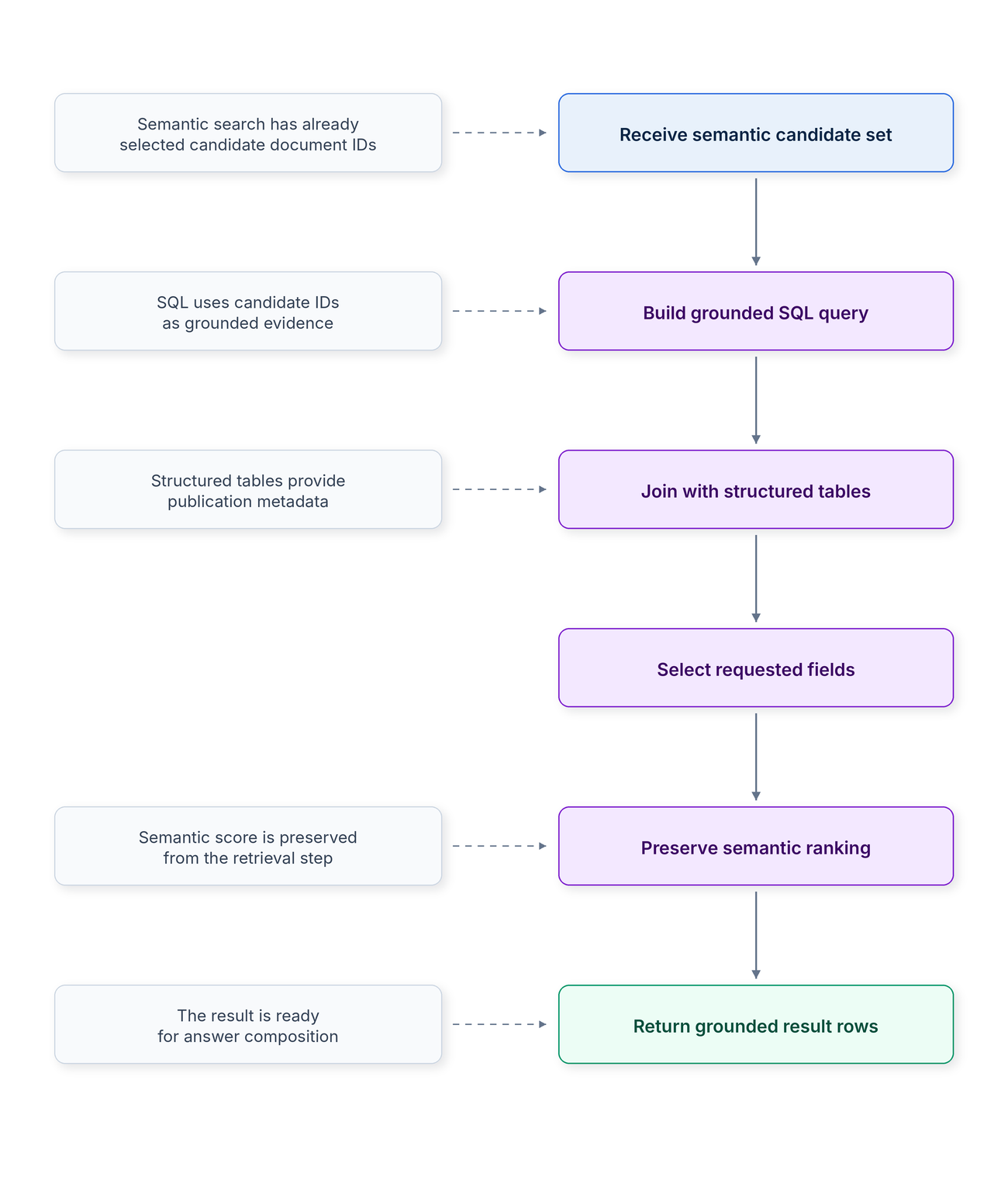
The semantic candidate set contains document IDs and scores.
But the user asked for publication fields:
title
publication year
source name
citation count
semantic score
The semantic index may contain some metadata, but the source SQL database remains the system of record.
So the agent builds a SQL query that joins the candidate IDs back to the OpenAlex tables.
A simplified version of the final SQL looks like this:
WITH semantic_candidates (
document_id,
semantic_rank,
semantic_score
) AS (
VALUES
('https://openalex.org/W2950067395', 1, 0.895867),
('https://openalex.org/W2443450302', 2, 0.669739),
('https://openalex.org/W2922266198', 3, 0.661938),
('https://openalex.org/W2977173717', 4, 0.639299),
('https://openalex.org/W2135577628', 5, 0.633553)
)
SELECT
w.title,
w.publication_year,
w.source_name,
w.cited_by_count,
sc.semantic_score
FROM semantic_candidates sc
JOIN works w
ON w.id = sc.document_id
WHERE w.language = ‘en'
AND w.publication_year >= 2016
ORDER BY sc.semantic_rank
LIMIT 10;There are two things worth noticing here.
First, the SQL query does not try to recreate semantic search using `LIKE`.
It does not do this:
WHERE topic_name ILIKE '%natural language interfaces for databases%'That would be a different operation. It would not preserve the semantic score from the retrieval step, and it would not be equivalent to vector search.
Second, the SQL query keeps the metadata filters:
WHERE w.language = 'en'
AND w.publication_year >= 2016Even though the semantic search was already filtered, keeping the SQL filters is useful as a final grounding check.
The semantic index is a projection. The source database remains the truth.
The SQL step confirms that the returned publications are still valid according to the structured constraints.
Step 5: final answer composition
After SQL execution, the agent has a small table of grounded rows.
A reduced version of the result looks like this:
{
"rows": [
{
"title": "A comparative survey of recent natural language interfaces for databases",
"publication_year": 2019,
"source_name": "The VLDB Journal",
"cited_by_count": 168,
"semantic_score": 0.895867
},
{
"title": "Computer-Assisted Query Formulation",
"publication_year": 2016,
"source_name": "Foundations and Trends® in Programming Languages",
"cited_by_count": 9,
"semantic_score": 0.669739
},
{
"title": "NADAQ: Natural Language Database Querying Based on Deep Learning",
"publication_year": 2019,
"source_name": "IEEE Access",
"cited_by_count": 31,
"semantic_score": 0.661938
}
],
"grounding": {
"semantic_candidates_are_not_final_answers": true,
"final_answer_uses_sql_rows": true,
"metadata_filters_applied_before_vector_search": true,
"metadata_filters_confirmed_in_sql": true
}
}The assistant can now produce a user-facing answer:
I found English-language publications from 2016 onwards that are semantically related to natural language interfaces for databases. The most relevant result is “A comparative survey of recent natural language interfaces for databases”, published in 2019 in The VLDB Journal, followed by related work on query formulation and natural language database querying.
The exact final answer can be formatted as a table, because the user asked for structured fields.
But the important part is not the formatting.
The important part is the evidence path:
natural language request
→ grounded filters
→ filtered semantic retrieval
→ candidate IDs
→ SQL join
→ structured result rows
→ final answer
Why this example matters
This example is useful because it shows the difference between a demo and a data assistant that can be debugged.
A simple vector search demo could return plausible publications.
A simple SQL agent could generate a query.
But this flow does something more interesting.
It keeps the boundaries explicit:
Semantic search handles meaning.
SQL handles structure.
Filter grounding connects natural language to database values.
The agent orchestrates the workflow.
The final answer is based on executed SQL results.
That boundary is important.
Without it, the system can easily drift into one of two bad patterns.
The first bad pattern is trying to solve semantic questions with brittle SQL:
LOWER(title) LIKE '%natural language interfaces for databases%'That misses paraphrases and related terminology.
The second bad pattern is letting the vector index become the answer engine.
That makes it hard to enforce structured filters, joins, counts, permissions and auditability.
The hybrid pattern avoids both extremes.
Semantic search is used as candidate generation.
SQL is used for grounding.
The subtle bug this example exposed
This example also exposed a subtle but important failure mode.
The user said:
English-language publications
The first naive interpretation was:
language = ‘English’
But the OpenAlex data uses:
en
as the canonical value.
That means the agent must not blindly trust natural language literals.
It has to ground them.
This is especially important for categorical columns:
language
country
status
type
region
category
source
Natural language values often do not match stored database values exactly.
The user may say:
English
while the database stores:
en
The user may say:
United States
while the database stores:
US
The user may say:
closed deals
while the database stores:
Closed Won
A robust assistant needs a way to inspect observed values and canonicalize filters before using them.
In this example, that is what happened:
{
"field": "language",
"natural_value": "English",
"observed_canonical_value": "en",
"applied_value": "en"
}This is not just a convenience feature.
It directly affects retrieval quality.
If the semantic search runs with the wrong metadata filter, it can return no candidates or the wrong candidates. If it runs without filters, it can waste the top-k window on irrelevant documents.
So filter grounding has to happen before semantic search, not after.
What this says about the architecture
The previous post described the direction I wanted to move toward: filtered semantic retrieval.
This example shows that pattern working in a concrete case.
The semantic projection contains enough metadata to filter before vector ranking:
language
publication_year
document_id
source table
embedding
That allows the agent to ask the retrieval layer:
Search for this concept, but only inside English publications from 2016 onwards.
Instead of:
Search everything, then let SQL discard most of it later.
That difference matters because vector retrieval is top-k based.
If the search space is too broad, good candidates inside the structured subset may never appear in the candidate window.
By pushing metadata filters into the semantic search step, the system improves both efficiency and relevance.
The architecture becomes:
Source SQL database
→ controlled semantic projection
→ metadata-filtered vector retrieval
→ SQL evidence query
→ grounded answer
The semantic projection is not a replacement for the database.
It is a carefully synchronized retrieval layer.
That is the balance I want in DataTerreno:
keep the database as the source of truth;
give the agent semantic discovery capabilities;
preserve traceability and auditability;
avoid turning the vector index into an uncontrolled data copy.
What I would improve next
This example is a good milestone, but it is not the end of the work.
A few areas are still worth improving.
First, the ranking can be refined. The top results are strong, but later results can become more peripheral. That is normal in semantic retrieval, but there is room for better reranking.
Second, the system should expose filter canonicalization more explicitly in traces. It is useful to know not only that the final filter was `language = ‘en’`, but also why the system changed `English` to `en`.
Third, semantic search should continue evolving from a simple vector lookup into a controlled retrieval subsystem with:
metadata filters
phrase-aware reranking
source-key grounding
tenant and user scope
synchronization status
debug traces
Fourth, evaluation matters. It is not enough for the assistant to return something plausible. We need benchmarks that test whether semantic candidates are relevant, filters are applied before retrieval, and final SQL results are grounded.
That is the kind of boring but necessary work that makes the system trustworthy.
Final thought
This example is small, but it captures the core idea.
The user asks a natural language question.
The assistant does not simply translate it into SQL.
It does not simply ask a vector database for an answer.
Instead, it decomposes the request:
What is semantic?
What is structured?
Which filters need grounding?
Which tool should produce candidate evidence?
Which database query should return final rows?
That decomposition is where the value of the agent appears.
The agent is not useful because it can write a fancy query.
It is useful because it can coordinate multiple evidence paths while keeping the final answer grounded in real data.
That is the direction I want to keep exploring.
Because “talk to your data” sounds simple.
But the real challenge is not talking.
The real challenge is knowing when meaning belongs to semantic search, when structure belongs to SQL, and how to keep both connected without losing control.