
When SQL Is Not Enough: Exploring Hybrid SQL + Semantic Search in an Agent
Using semantic retrieval as a candidate generator, without giving up SQL as the source of truth

In the previous post I wrote about the motivation behind DataTerreno: building systems that make data easier to use without giving up control over it.
This post goes one layer deeper.
The question I am exploring now is very specific:
Does it make sense to introduce hybrid SQL + semantic search inside a data agent?
Not as a replacement for SQL. Not as a magic vector database that suddenly understands the business. And definitely not as a shortcut to skip data modelling.
The idea is more modest:
Use semantic search to find candidate rows when the user asks fuzzy, conceptual or free-text questions, and then use SQL to validate, filter, join, aggregate and produce the final grounded evidence.
That distinction matters.
Semantic search is good at finding things that are about something. SQL is good at computing exact answers over structured data. A useful agent needs both, but it also needs to know where one ends and the other begins.
The limitation I hit with plain SQL agents
A classic SQL agent works reasonably well when the question maps cleanly to relational operations.
For example, in a CRM database:
How many opportunities were closed last month?
That is a natural fit for SQL:
SELECT COUNT(*)
FROM opportunities
WHERE status = ‘Closed Won’
AND close_date >= DATE ‘2026-04-01’
AND close_date < DATE ‘2026-05-01’;The user asks for a count. The database has a status column and a date column. SQL is exactly the right tool.
But real questions are often messier:
Show me the opportunities related to cloud migration from last quarter.
Now we have two different kinds of intent mixed together:
Structured filtering: “from last quarter”.
Semantic matching: “related to cloud migration”.
The date filter belongs in SQL. The concept “cloud migration” may be hidden inside fields like opportunity notes, project description, meeting summaries or customer requirements.
Trying to solve this with only SQL usually means falling back to brittle LIKE predicates:
WHERE LOWER(description) LIKE ‘%cloud%’
OR LOWER(description) LIKE ‘%migration%’That works for obvious cases, but it misses synonyms, paraphrases and domain language:
workload modernization
move from on-prem to hosted infrastructure
data center exit
application replatforming
hybrid cloud adoption
This is where semantic search starts to make sense.
The high-level idea
At a high level, the agent should not choose between SQL and semantic search. It should orchestrate both.
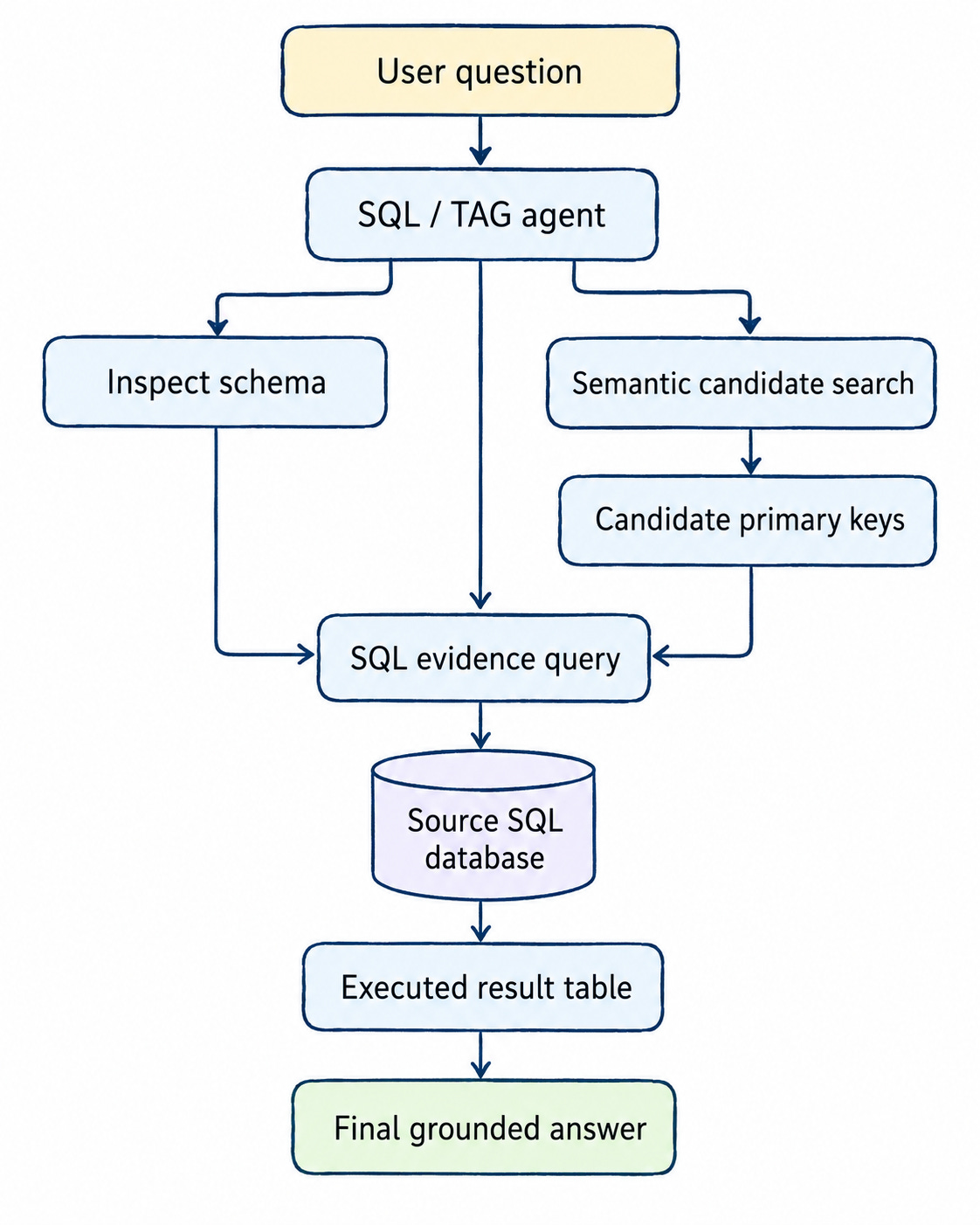
The semantic index does not answer the question. It only says:
These rows look semantically relevant.
The source database still has to answer:
Which of those rows actually match the structured constraints, permissions, joins and aggregations required by the user?
That is the core design principle I am using.
What we have implemented so far
In the current backend, the SQL agent is implemented as a self-contained TAG-style agent.
The flow is roughly:
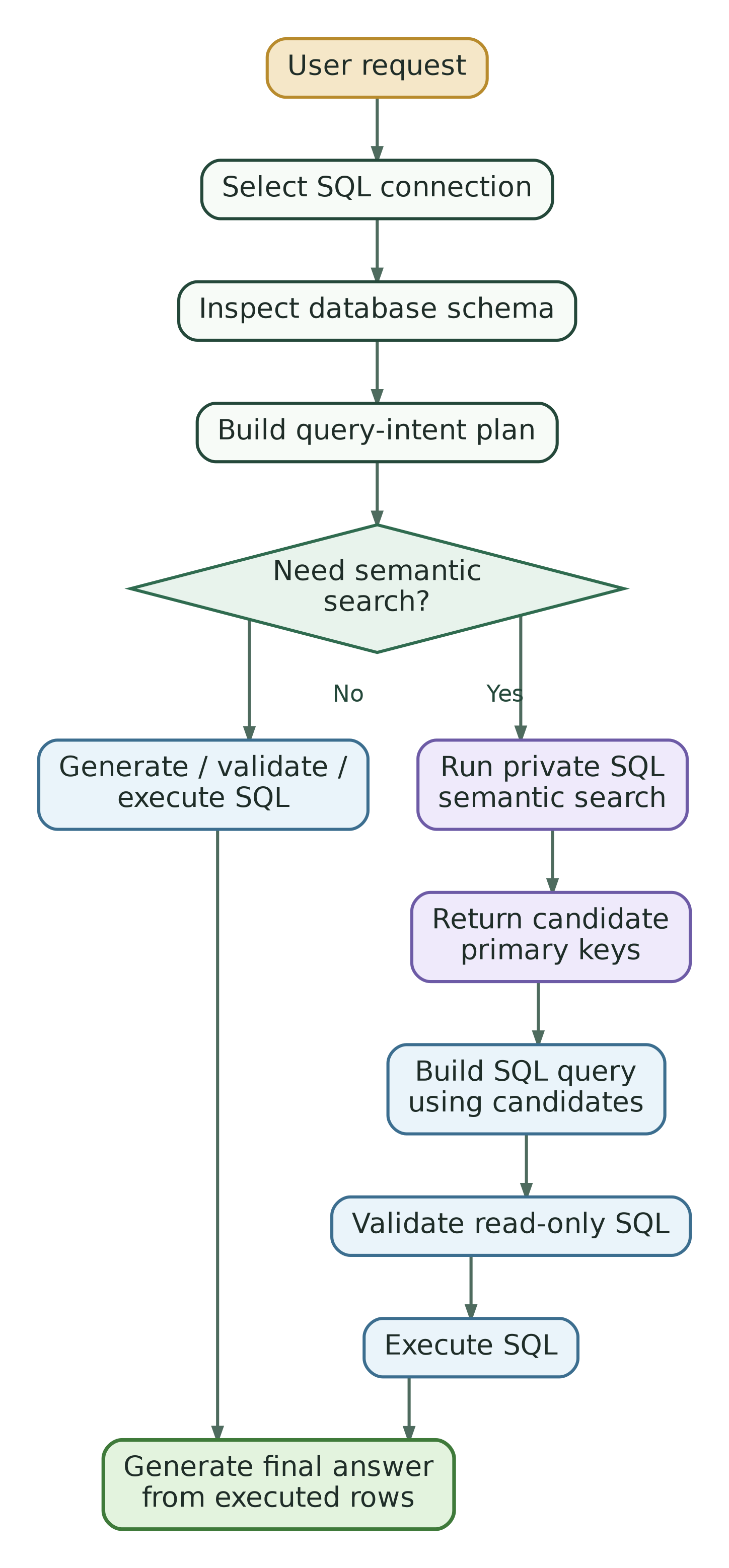
A few details are important.
First, semantic search is exposed as an internal agent tool called sql_semantic_search. Its job is to search a private semantic index for configured SQL table rows. It returns candidate matches, primary keys, semantic rank, similarity and a ready-to-use SQL CTE snippet.
Second, the final answer is not allowed to come directly from the semantic index. The tool contract is explicit: semantic matches are private candidate rows; SQL execution over the configured database is still required for final row values, counts, joins and aggregations.
Third, the SQL agent validates every query before execution. The validator only accepts read-only SELECT or WITH statements and rejects dangerous operations such as INSERT, UPDATE, DELETE, DROP, ALTER, COPY, LOAD, PRAGMA, and similar commands.
This is not just a safety detail. It is what keeps the agent grounded in a controlled data workflow instead of turning it into a free-form code generator connected to a database.
Choosing what to index
One of the first architectural decisions is deciding which columns deserve semantic indexing.
Not every column should be embedded.
Good candidates are columns that contain free text and where exact matching is likely to fail:
case descriptions
opportunity notes
support tickets
product reviews
contract descriptions
tender titles
meeting summaries
customer requirements
Poor candidates are columns that already have precise structure:
dates
numeric amounts
foreign keys
status codes
identifiers
booleans
controlled categorical values
In the backend this is configured per SQL connection using a semantic profile. A table can enable semantic search and declare its primary key and text columns.
A simplified CRM-style configuration would look like this:
{
“connections”: [
{
“name”: “crm”,
“dialect”: “postgresql”,
“connection_uri”: “postgresql://...”,
“default_schema”: “public”,
“semantic_profile”: {
“tables”: {
“opportunities”: {
“primary_key”: [”opportunity_id”],
“semantic_search”: {
“enabled”: true,
“text_columns”: [”title”, “description”, “next_steps”],
“batch_size”: 500
}
}
}
}
}
]
}The important part is that this is explicit. The system should not blindly embed every column in every table. That would create noise, increase cost and make the retrieval layer harder to reason about.
Mapping semantic candidates back to real rows
Once a row is embedded, we need a stable way to map the vector back to the original data.
In the current implementation, each indexed row is linked to the source table through:
tenant id
user id
connection name
source schema
source table
source key
source key hash
The source key is derived from the configured primary key. If the table has a simple primary key, the source key can be just that value. If the table uses a composite key, the key is serialized as a JSON array.
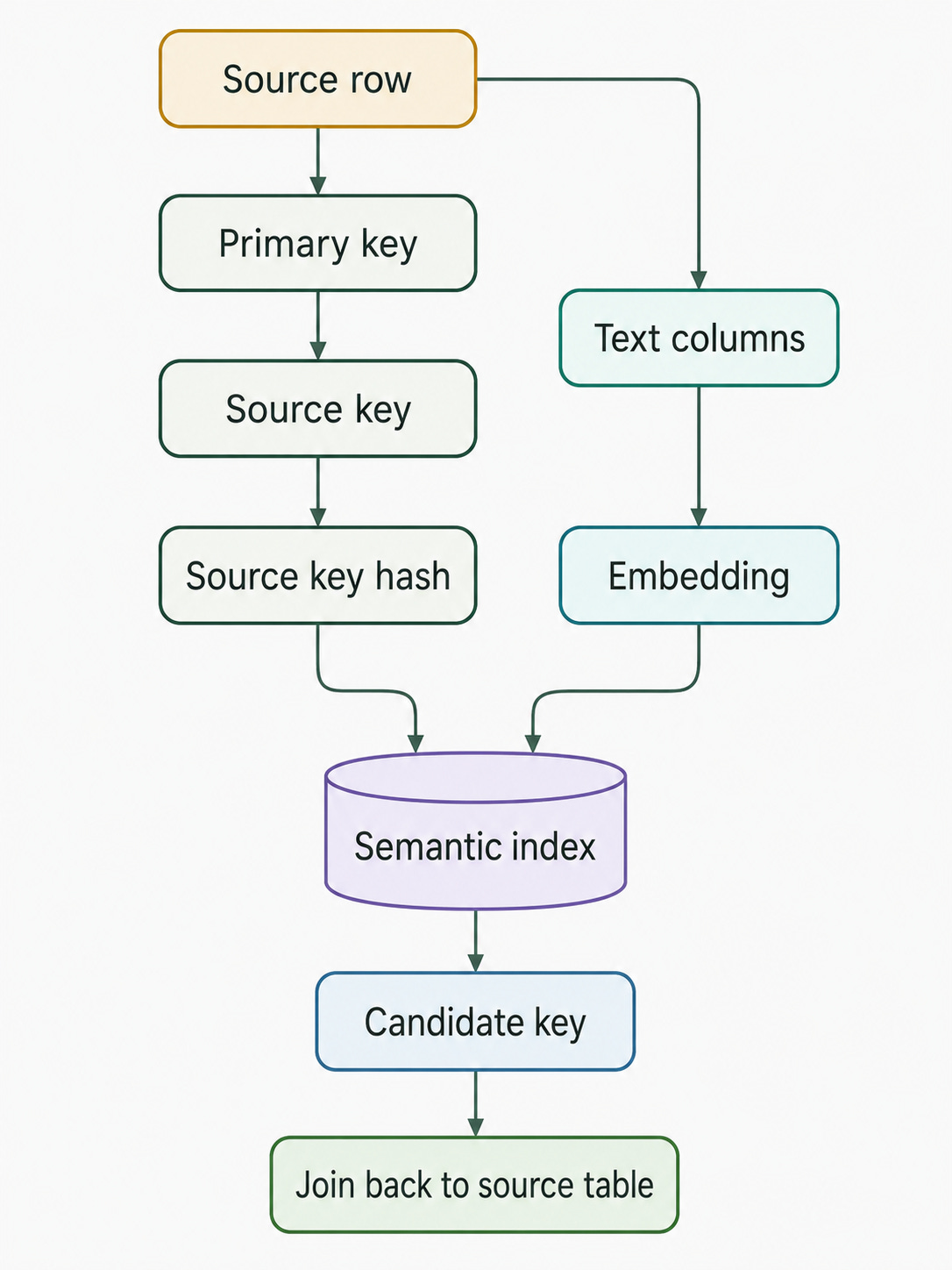
This is a small but critical detail.
The semantic index should not become a second source of truth. It should behave more like a search accelerator. It helps the agent find candidates, but the source database is still responsible for returning the actual rows.
That also keeps the index compact. The current model stores the vector, source identity, content hash, embedding model and synchronization metadata. It does not keep a full duplicated copy of the original row.
That is good for control and simplicity, but it also creates one of the next challenges: filter pushdown.
More on that later.
Why CTEs are useful here
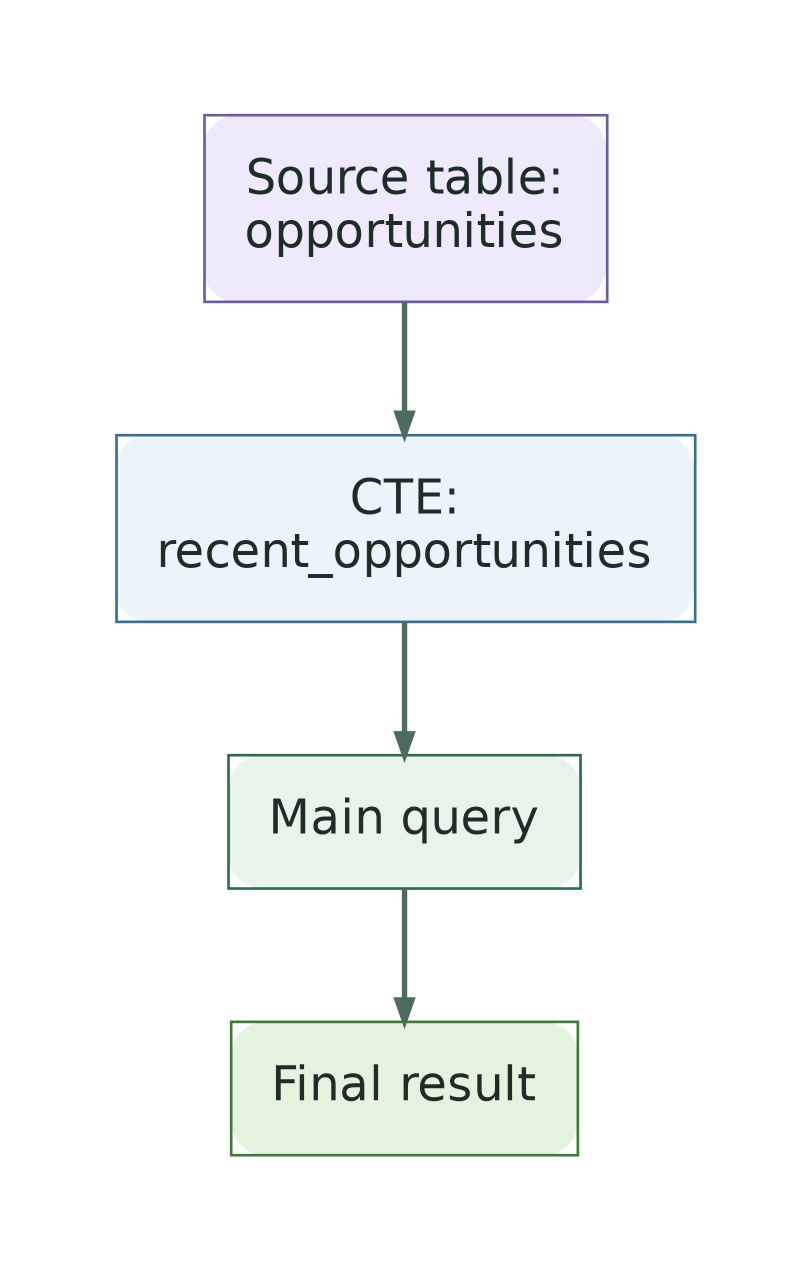
A CTE, or Common Table Expression, is a temporary named result set inside a SQL query.
It is defined using WITH and can then be referenced by the main query.
Simple example:
WITH recent_opportunities AS (
SELECT *
FROM opportunities
WHERE close_date >= DATE ‘2026-04-01’
)
SELECT owner_id, COUNT(*)
FROM recent_opportunities
GROUP BY owner_id;You can think of it as a readable intermediate step:
In our hybrid SQL + semantic search flow, CTEs are useful because the semantic tool can return a small candidate set as a SQL fragment.
For example:
WITH semantic_candidates_opportunities(
opportunity_id,
semantic_rank,
semantic_similarity
) AS (
VALUES
(’OPP-001’, 1, 0.91),
(’OPP-017’, 2, 0.88),
(’OPP-042’, 3, 0.84)
)
SELECT
o.opportunity_id,
o.title,
o.stage,
o.close_date,
sem.semantic_rank,
sem.semantic_similarity
FROM opportunities o
JOIN semantic_candidates_opportunities sem
ON o.opportunity_id = sem.opportunity_id
WHERE o.close_date >= DATE ‘2026-04-01’
AND o.close_date < DATE ‘2026-05-01’
ORDER BY sem.semantic_rank;The CTE acts as a bridge between the semantic retrieval layer and the relational database.
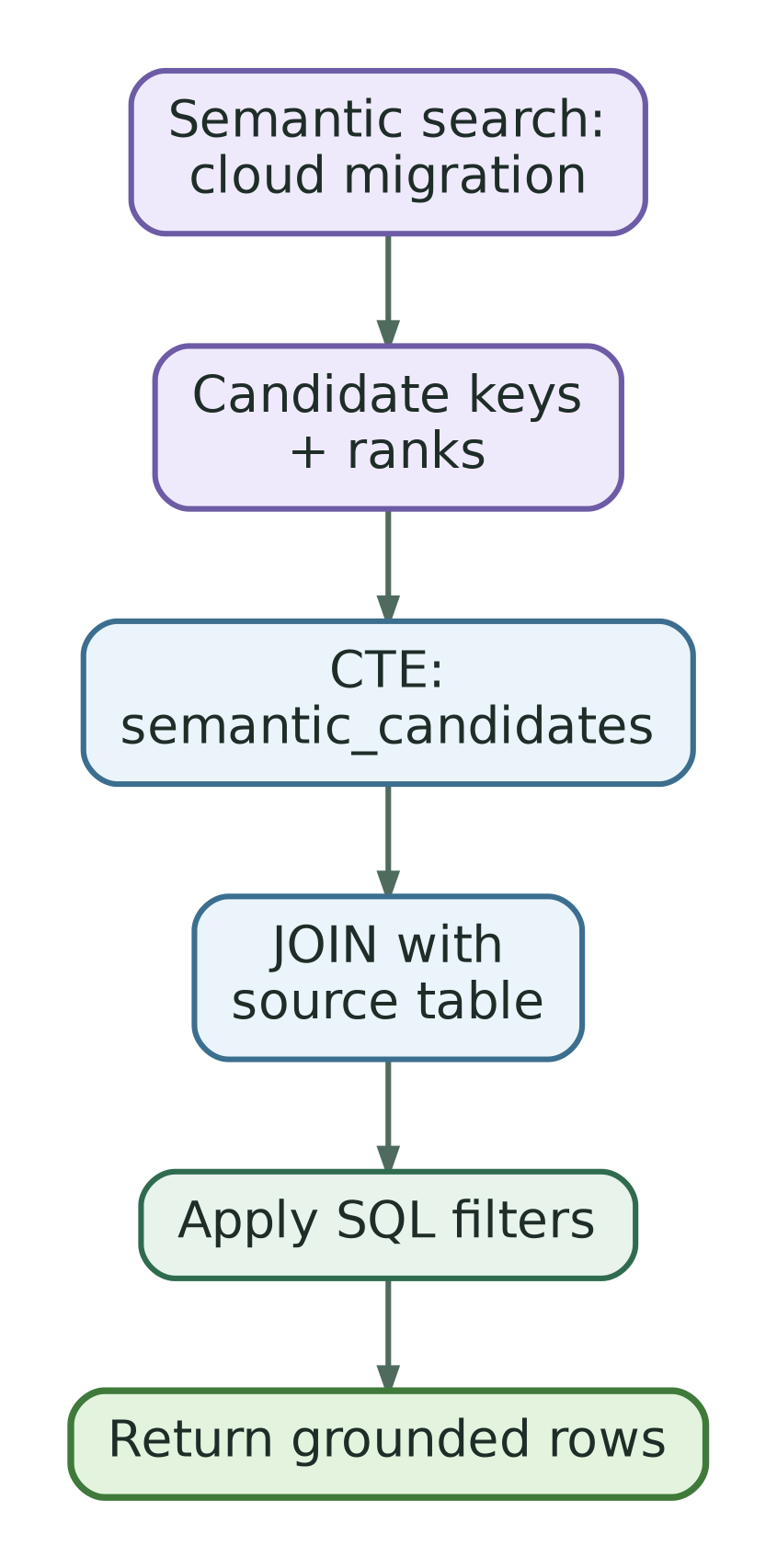
This pattern is simple, debuggable and portable enough to test across different SQL engines.
It is also very useful for agents because the CTE is explicit. The model does not need to invent a vector function inside SQL. It receives concrete candidate keys and joins them back to the source table.
The filtering problem
Now comes the interesting part.
Suppose the user asks:
Find sales of products related to technology during last month.
There are two possible execution strategies.
The naive strategy is:
Run semantic search for “technology” across all products.
Get the top semantic candidates.
Use SQL to filter those candidates to last month’s sales.
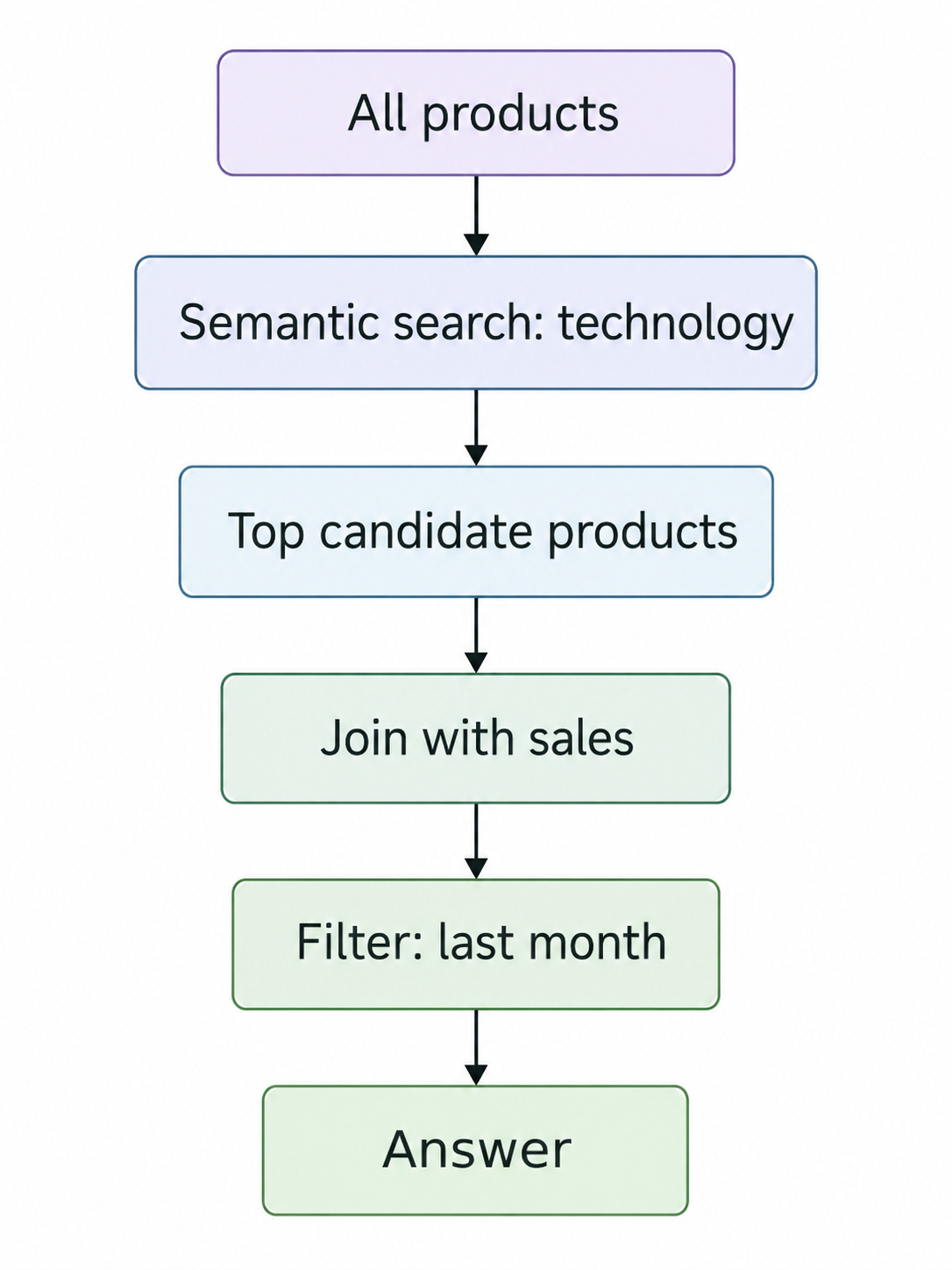
This works, but it can be inefficient and noisy.
Why?
Because the semantic search was performed over the full product universe, not over the subset of products that were actually sold last month.
The top semantic results may include products that are conceptually related to technology but irrelevant to the time window. By the time SQL applies the date filter, many good candidates may already have been lost because the vector search spent its top-k budget on rows outside the structured constraint.
The better strategy is:
Use SQL-like filters first to restrict the candidate universe.
Run semantic search only inside that filtered universe.
Return candidates that are both semantically relevant and structurally valid.
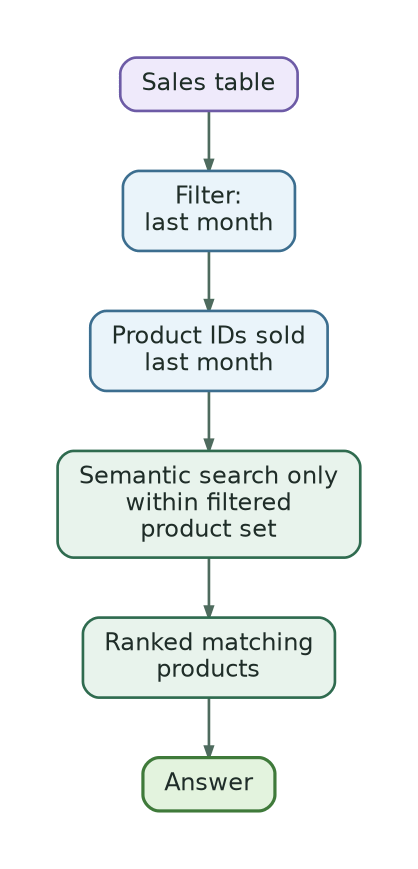
This is the architectural tension.
To do filtered semantic search efficiently, the semantic index needs to know more than just embeddings. It also needs enough structured metadata to apply filters before vector search:
dates
tenant / user scope
source table
identifiers
foreign keys
status fields
maybe some categorical dimensions
That means the semantic index starts to look like a synchronized projection of part of the SQL database.
And that requires a synchronization mechanism.
Where the current implementation stands
The current backend already has the synchronization mechanism for semantic indexing.
It scans configured source tables in batches, extracts the configured primary key and text columns, builds an embedding payload from the text, computes hashes, calls the embedding provider in batches and upserts rows into a PostgreSQL/pgvector-backed semantic index.
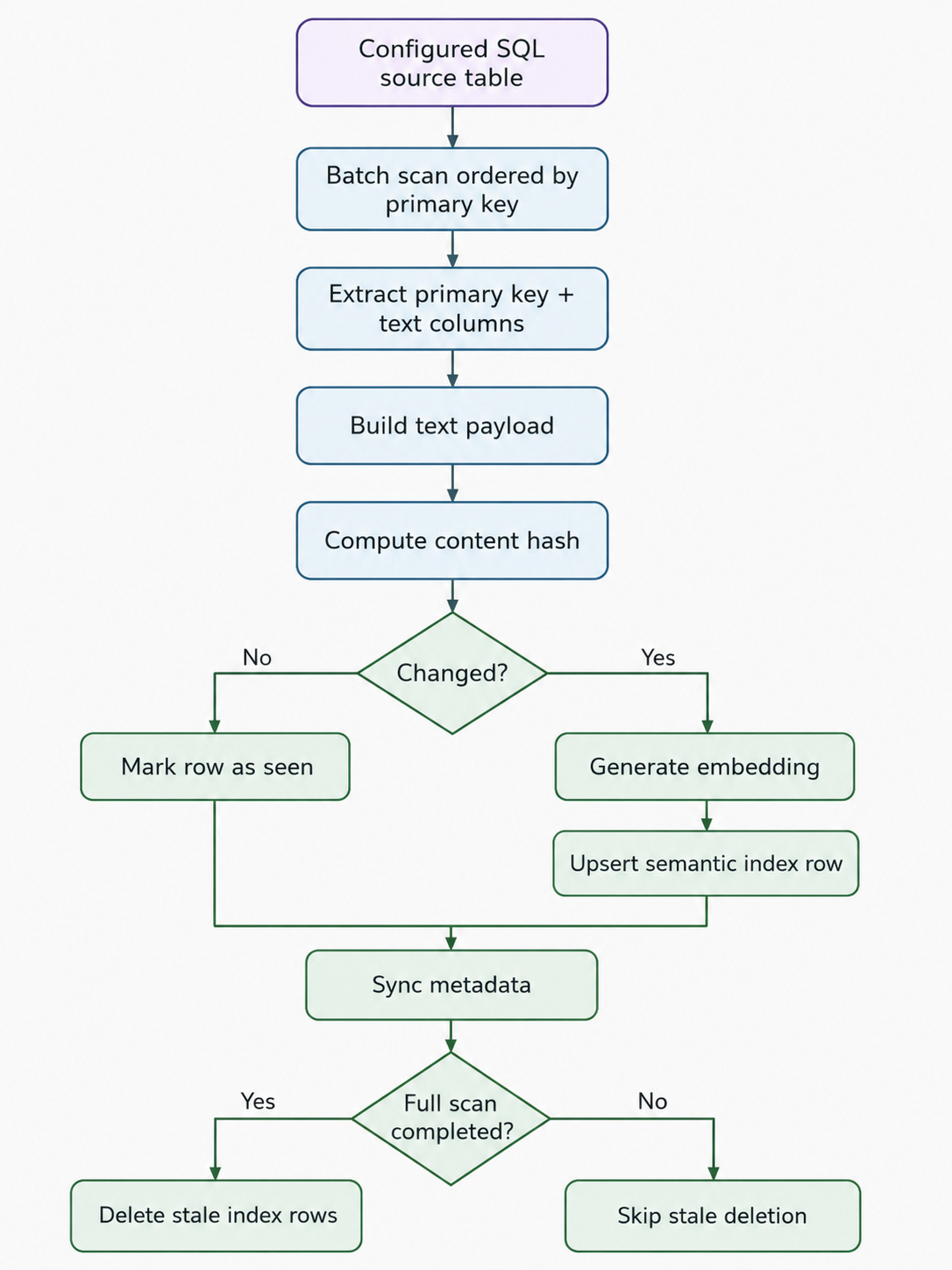
The index is scoped by tenant and user. That is important because semantic retrieval is not a public search operation. It happens inside the user’s private context.
The current implementation also keeps the semantic index intentionally compact. Legacy payload columns are cleared when possible, and the index keeps the source key and embedding metadata rather than becoming a full copy of the source table.
That is a good first step.
But it also means that full filter pushdown is not implemented yet.
At query time, the current agent usually does this:
Run semantic search across the configured semantic table.
Get candidate primary keys.
Build a CTE with those candidates.
Join the CTE back to the source table.
Apply SQL filters such as dates, status or exact identifiers.
Generate the final answer only from executed SQL results.
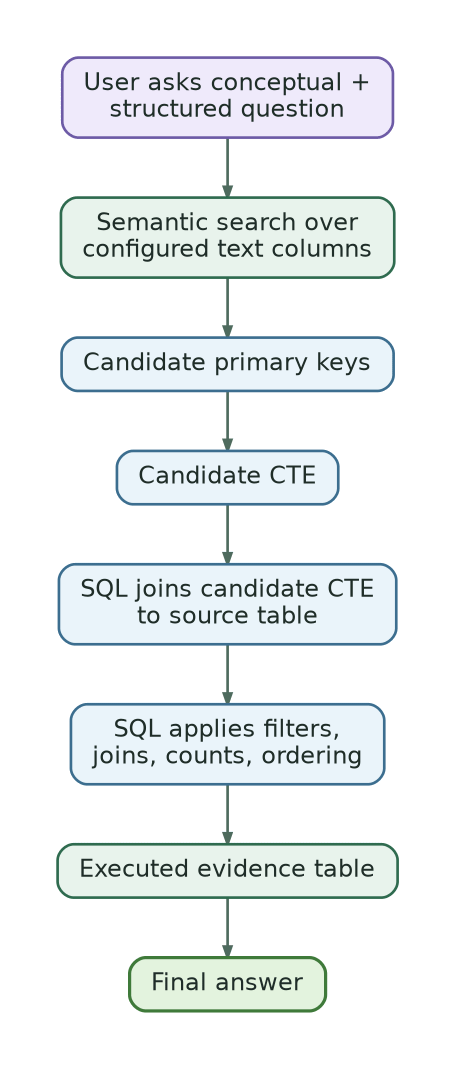
This gives us grounding and correctness control, but not always optimal retrieval efficiency.
If the structured filter is very selective, we still pay the cost of searching the broader semantic space first. The SQL filter happens after candidate retrieval, not before it.
So the current implementation is a working hybrid pattern, but not the final optimized version.
Why not just put everything into the vector database?
One possible reaction is:
Why not store all fields in the vector database and query everything there?
Because then we risk rebuilding a weaker database next to the real one.
SQL databases already know how to filter, join, count, sort, group, aggregate and enforce structure. Vector databases are useful, but they should not become the place where we reimplement relational semantics badly.
The more useful direction, at least for what I am exploring, is a controlled projection:
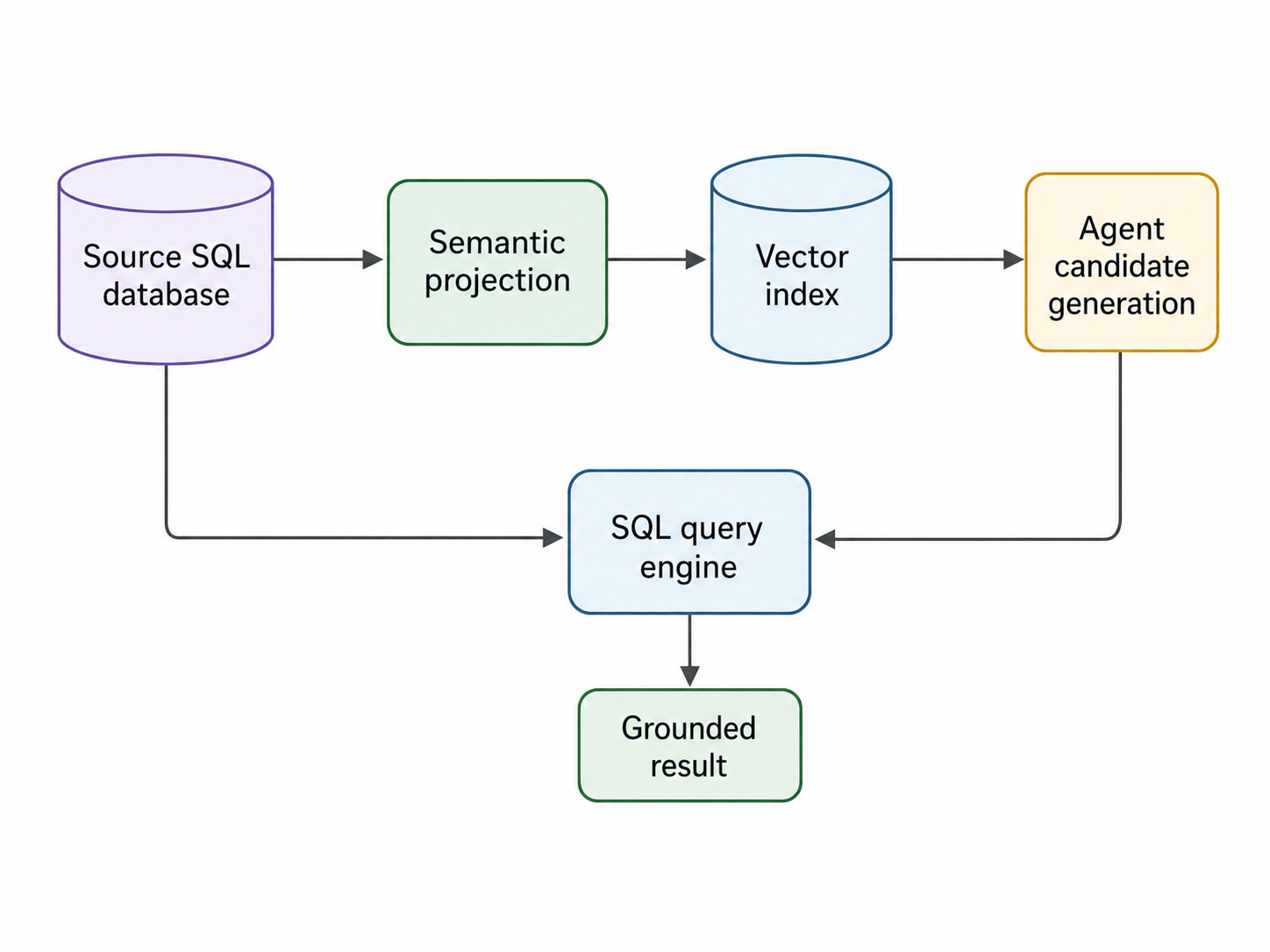
The projection should contain only what semantic retrieval needs:
the embedding
the source key
enough metadata to pre-filter safely
synchronization hashes
scope and ownership fields
Not the whole operational dataset.
This keeps a clear boundary:
SQL remains the system of record.
The semantic index remains an acceleration and discovery layer.
The agent orchestrates both.
The role of filter columns
The backend already has the concept of profile-declared filter columns at the agent level.
This is useful when the user explicitly scopes a value to a field.
For example:
Show opportunities where customer is ACME Corp.
The word “ACME Corp” should not be treated as a broad semantic concept. It is an exact field constraint. The agent should bind it to the configured source column, such as customer_name, and use SQL.
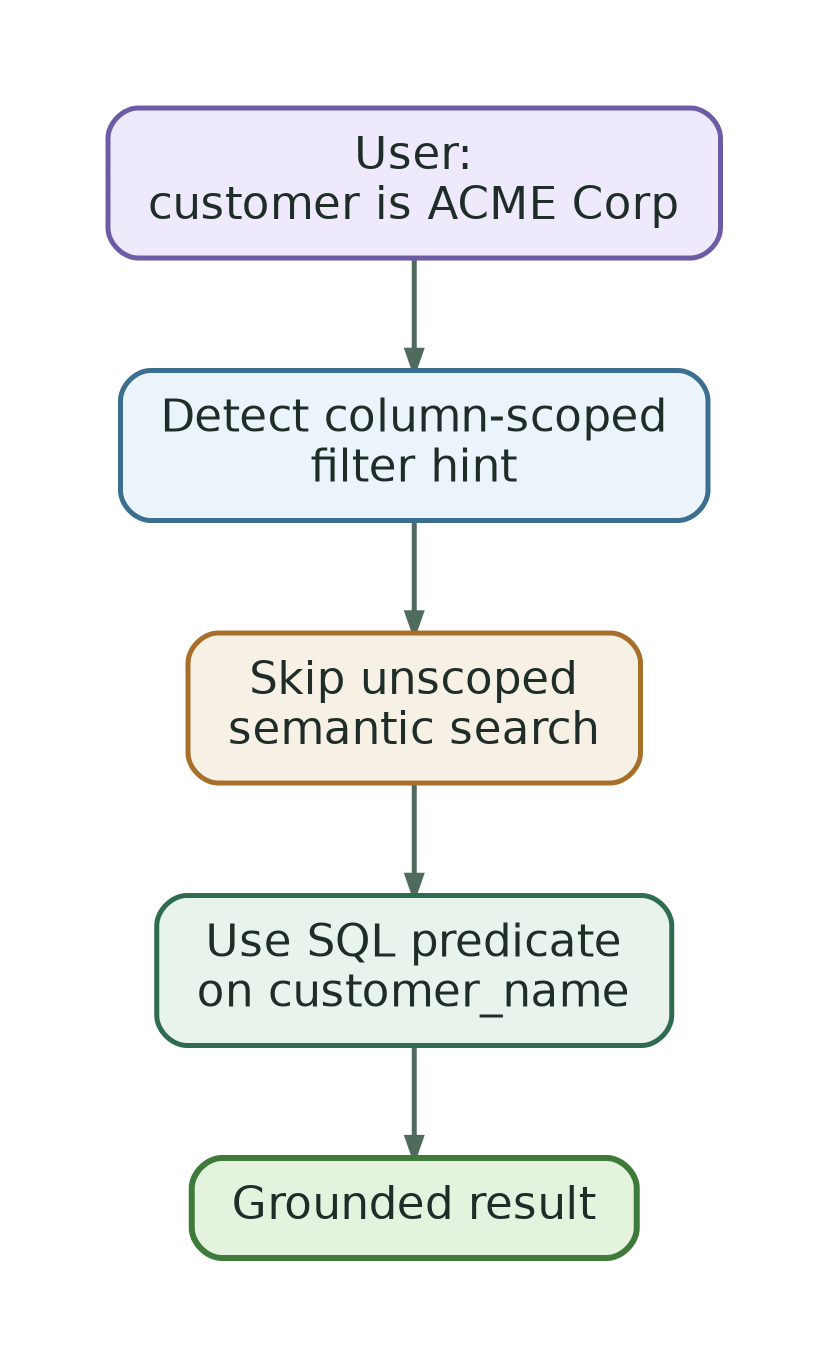
This avoids a common failure mode: using semantic search when the user actually gave an explicit structured condition.
However, this is different from true metadata filtering inside the semantic index.
Today, the agent can use filter hints to decide when not to run semantic search, or how to apply SQL constraints after candidates are retrieved. The next optimization step is to persist selected filterable metadata in the semantic index itself so that semantic retrieval can be narrowed before vector ranking.
That would make questions like this more efficient:
Show support cases related to authentication errors opened last week.
Instead of searching every support case ever indexed, the semantic search could first restrict the index to cases opened last week, then rank only that subset for “authentication errors”.
A possible next architecture
The next version of the hybrid search layer could look like this:
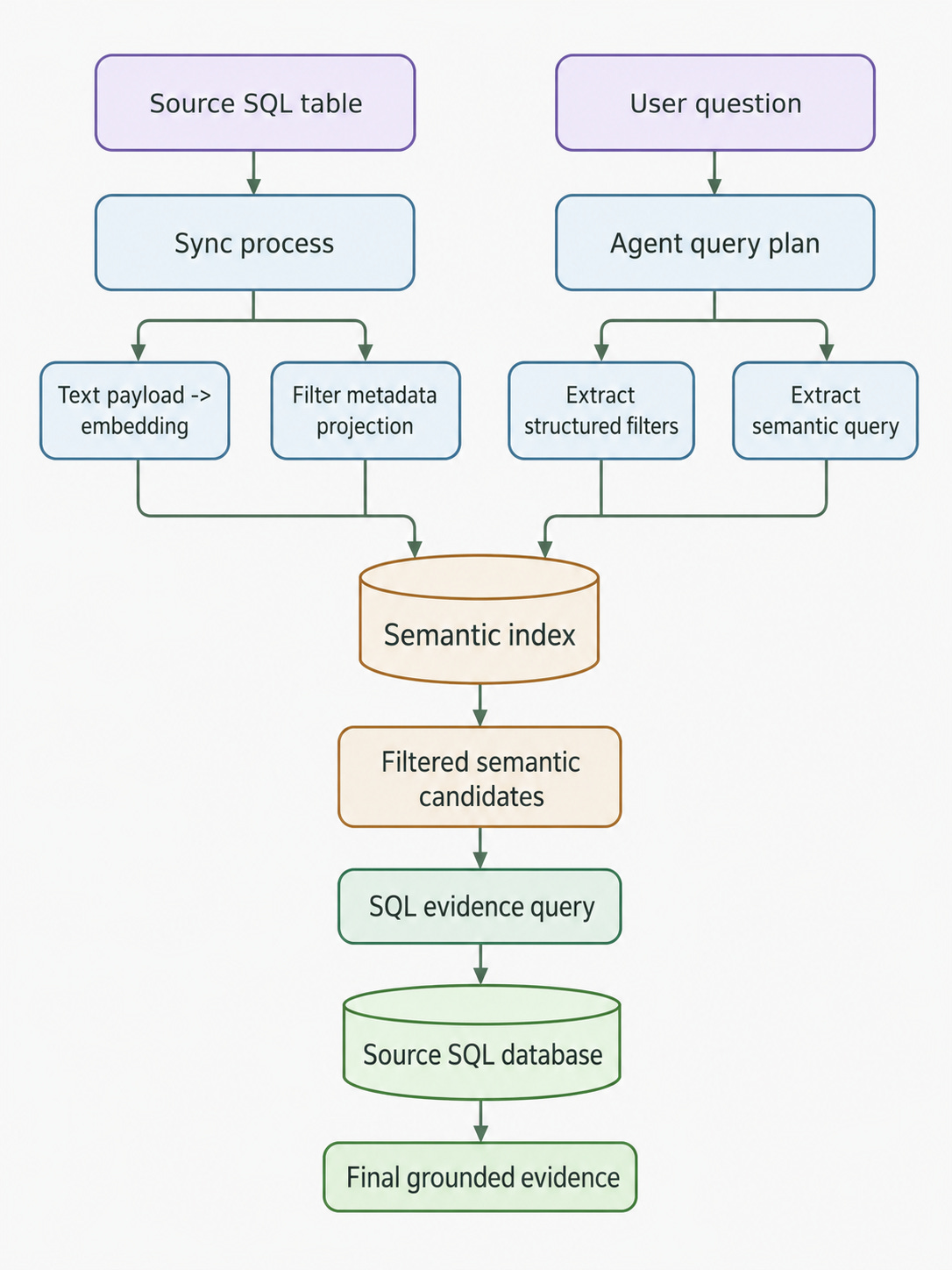
In a CRM example, the semantic projection for opportunities might include:
embedding: vector(description + notes + next_steps)
source_key: opportunity_id
source_table: opportunities
owner_id: structured metadata
account_id: structured metadata
stage: structured metadata
close_date: structured metadata
created_at: structured metadata
updated_at: structured metadata
Then the agent can push down filters like:
last month
account = ACME
owner = Maria
stage = Closed Won
region = EMEA
before ranking semantically.
That reduces noise, improves recall inside the relevant subset and avoids wasting the top-k semantic window on rows that SQL will later discard.
But synchronization becomes a real subsystem
The moment we keep a semantic projection of SQL data, we need to answer uncomfortable questions:
How often is the index refreshed?
Is synchronization full, incremental or event-driven?
How do we detect deleted rows?
What happens when the embedding model changes?
How do we avoid indexing stale data?
How do we handle permissions per tenant and user?
Which metadata columns are safe and useful to duplicate?
How do we avoid turning the semantic index into an uncontrolled data copy?
The current backend already deals with some of this.
It uses content hashes to detect whether a text payload changed. It tracks the embedding model, so rows can be refreshed when the model changes. It uses a synchronization run ID and last_seen_at metadata. It only deletes stale rows after a complete source scan, avoiding unsafe deletion after partial syncs. It supports batch sizes, embedding batch sizes, dry runs, row limits, batch limits and commit intervals.
That is the kind of boring machinery that makes the architecture real.
The exciting part is “talk to your data”. The hard part is keeping the index coherent enough that the assistant does not talk to yesterday’s data by mistake.
Why this belongs inside an agent
Hybrid SQL + semantic search could be implemented as a fixed pipeline, but an agent adds something useful: decision-making.
Not every question needs semantic search.
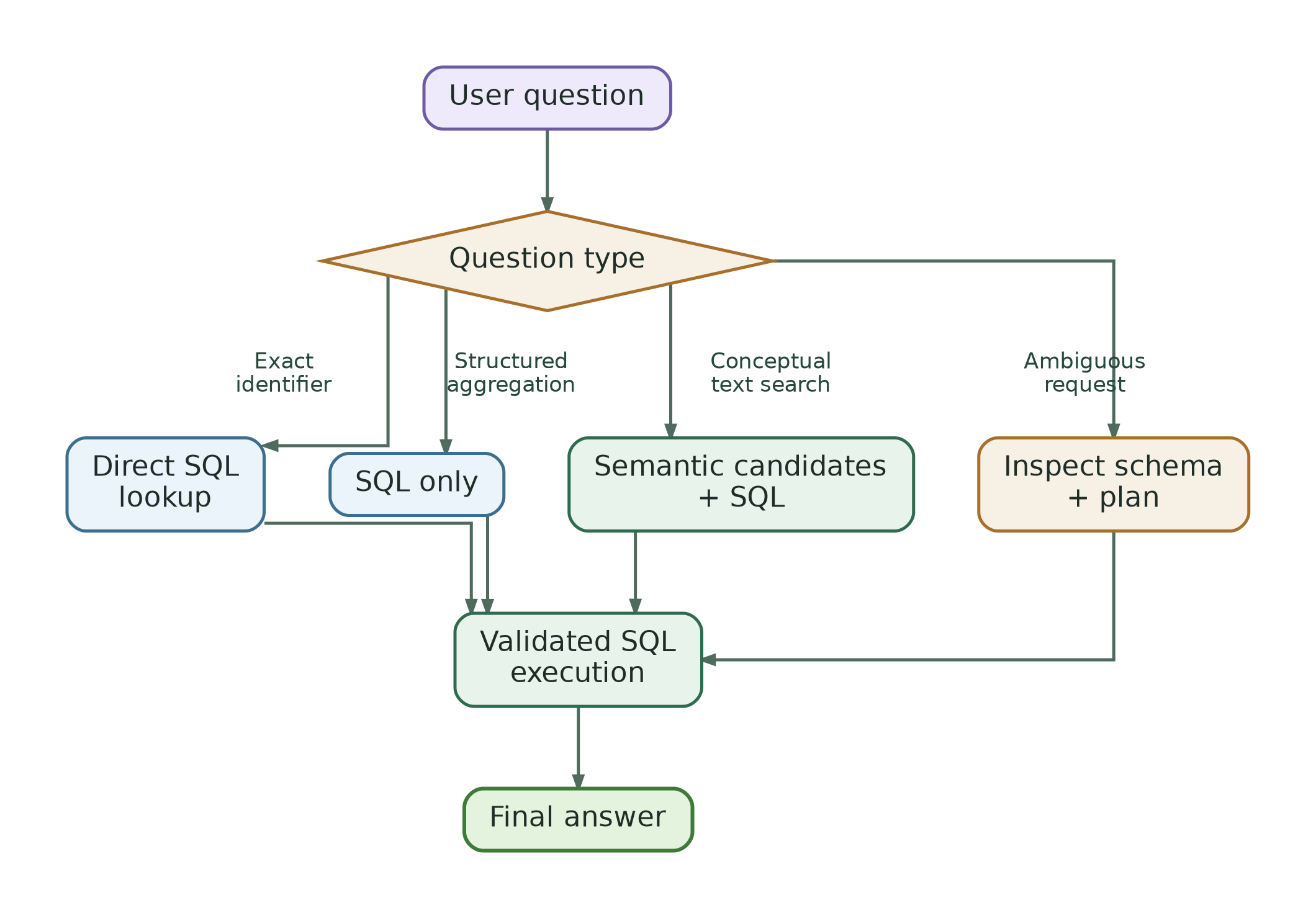
For example:
“Give me opportunity OPP-123” should be a direct identifier lookup.
“How many opportunities closed last month?” should be SQL only.
“Show opportunities related to cloud migration” may need semantic search.
“Show ACME opportunities related to authentication issues opened last week” may need both.
The agent’s job is not just to generate SQL. It has to decide which evidence path makes sense.
In the backend, this is handled through a query-intent plan. The agent extracts hints such as:
base table
text columns
identifier columns
literal terms
strong literal terms
date filters
whether the user wants a count, detail list or ranking
whether semantic search should be skipped
This is still heuristic and under active refinement, but it is already useful. It prevents some bad behavior, such as running semantic search for exact identifiers or treating a column-scoped filter as free text.
Semantic candidates are not counts
One important lesson: a semantic candidate set is not the same thing as a complete result set.
If the semantic tool returns 30 candidates, that does not mean there are only 30 matching rows in the database.
It means:
The semantic retriever returned 30 candidate rows under the current retrieval settings.
This distinction matters for questions like:
How many opportunities are related to cloud migration?
If we simply count the top 30 semantic candidates, we are not answering the question. We are counting the retrieval window.
The current implementation carries this warning explicitly in the semantic payload: the candidate count is not a full database count unless a separate SQL count over a complete predicate is executed.
This is one of the reasons I do not want the final answer to come directly from vector search. Retrieval is evidence discovery. SQL is where exact computation should happen.
The pragmatic trade-off
So, is hybrid SQL + semantic search inside an agent a good idea?
My current answer is:
Yes, but only if semantic search is treated as candidate generation, not as the source of truth.
The pattern solves a real problem: SQL agents struggle with conceptual free-text questions, and pure RAG struggles with structured computation. Combining them gives the agent a better chance of answering questions that contain both fuzzy meaning and exact constraints.
But it introduces new architectural complexity:
semantic profiles must be designed per table;
text columns must be selected carefully;
primary keys must be stable;
synchronization must be reliable;
stale rows must be handled safely;
filter pushdown requires metadata duplication;
query planning must decide when semantic search is useful;
final answers must remain grounded in executed SQL results.
This is not a free lunch.
It is more like adding a new implement to the data field: useful, but only if it is attached to the right machinery.
Where I am going next
The current implementation is a first working version, not the final design.
The next area I want to optimize is filtered semantic retrieval.
The goal is to move from this:

To this:

That requires extending the semantic index from a pure vector + source-key structure into a controlled, synchronized semantic projection with selected filterable fields.
I do not know yet if this will be the most efficient approach in every case. There may be better options depending on the database engine, vector backend, data volume, query pattern and latency constraints.
But this is the path I am exploring now.
It keeps the database in charge of structured truth. It gives the agent a way to work with meaning. And it preserves a clear architectural boundary between search, computation and answer generation.
That boundary is where most of the interesting work is happening.
Because “talk to your data” sounds simple.
But once the questions become real, the system has to cultivate both sides of the field: the structure of the database and the semantics of human language.