
Breaking Ground
Where data engineering meets AI: building tools to understand, protect, and grow your own knowledge

Why this blog exists
Data has become one of the most valuable assets any person, team or organization can own. But owning data is not the same as controlling it. And controlling it is not the same as understanding it.
That gap is where this blog starts.
Over the last few years, I have been working around data platforms, Data Lakehouse architectures, language models, conversational assistants and agentic AI. What began as an academic project - Talk to your data, a final degree project about Table-Augmented Generation - has gradually turned into a much broader exploration: how can we make data more accessible without giving up control over it?
That question is technical, but it is also strategic.
Because every time an organization moves its data, its models, its metadata, its identity layer or its analytical workflows into someone else’s black box, it gains convenience but loses part of its autonomy. Sometimes that trade-off makes sense. Sometimes it does not. But it should always be a conscious decision.
This blog is a place to document that journey.
Not as a collection of polished marketing stories, but as a field notebook: things tested, things broken, architectures explored, design decisions, failed assumptions, small discoveries, technical trade-offs and lessons learned while building systems around data sovereignty, AI and modern analytics.
The core idea: cultivate your own knowledge
At DataTerreno, the metaphor is simple: data is raw land.
You do not get value from land just by owning it. You need to work it. You need to prepare it, clean it, structure it, protect it and make it productive. The same happens with data.
Raw data is messy. It comes from different systems, in different formats, with different levels of quality and trust. Before it can support decisions, it needs engineering. Before it can feed AI, it needs context. Before it can become knowledge, it needs to be governed.
But there is a second part to the metaphor: the land is yours.
The point is not to hand over control of your data to intermediaries and hope for the best. The point is to build tools that allow organizations to understand, protect and grow their own knowledge without unnecessary dependencies.
That does not mean rejecting cloud, commercial platforms or managed services by default. It means avoiding blind dependency. It means keeping architectural options open. It means understanding what is happening under the hood. It means being able to decide where your data lives, who can access it, what models process it and how the results are audited.
Data sovereignty is not nostalgia for on-premises infrastructure. It is the ability to choose.
From “talk to your data” to agentic systems
The first major milestone in this journey was my final degree project: an assistant capable of interacting with structured data using natural language.
The original idea was simple to explain but difficult to implement well: what if a user could ask a database a question in plain language and receive a useful answer without knowing SQL, table schemas or query engines?
Classic Text-to-SQL is part of the answer, but not the whole answer. Translating a question into SQL works well when the question maps cleanly to relational operations. But real questions are often messier. They may require interpretation, classification, summarization, external knowledge or multi-step reasoning.
That is where Table-Augmented Generation becomes interesting.
TAG connects three worlds:
The precision of database systems.
The semantic flexibility of language models.
The conversational interface that makes data accessible to more people.
Instead of treating the language model as a magic box, the system must orchestrate it with tools: inspect schemas, generate queries, execute them, validate results and compose a final answer grounded in real data.
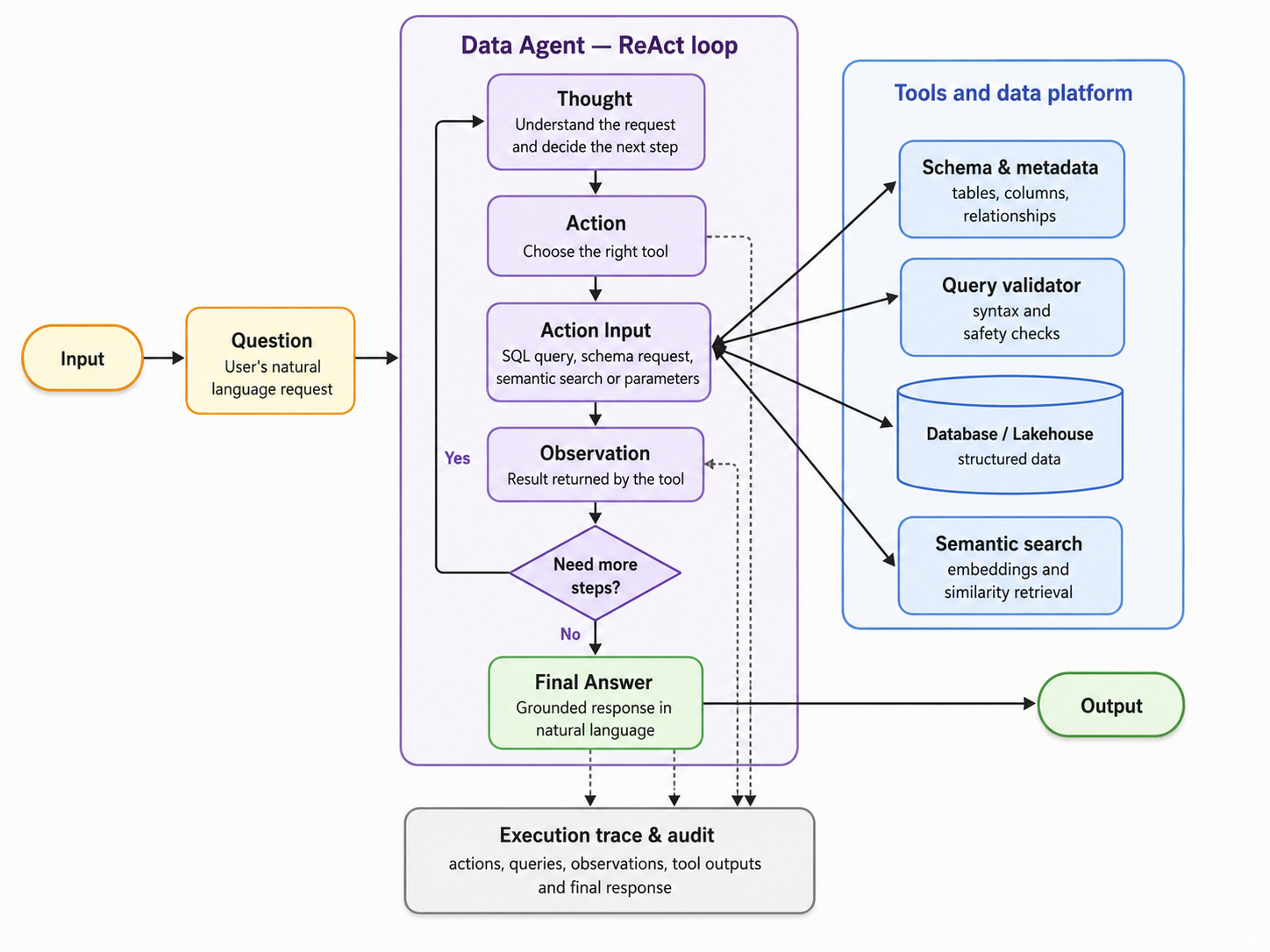
This naturally led to agentic patterns such as ReAct, where the model alternates between reasoning and acting. In practice, that means the assistant can think about the task, decide to inspect a schema, execute SQL, observe the result, correct itself if needed and then produce an answer.
That loop is where many interesting problems appear: hallucinations, invalid SQL, schema ambiguity, context limits, tool errors, infinite loops, unclear user intent, permission boundaries and evaluation difficulties.
Those problems are exactly the kind of material this blog will explore.
The platform underneath matters
A conversational assistant is only as useful as the data platform behind it.
That is why another line of work has focused on building and orchestrating an on-premises Data Lakehouse platform: object storage, metadata services, query engines, identity, permissions, deployment automation and operational visibility.
The goal is not to rebuild a hyperscaler from scratch. The goal is to understand which components are needed to run a modern data platform under your own control.
A typical pattern looks like this:
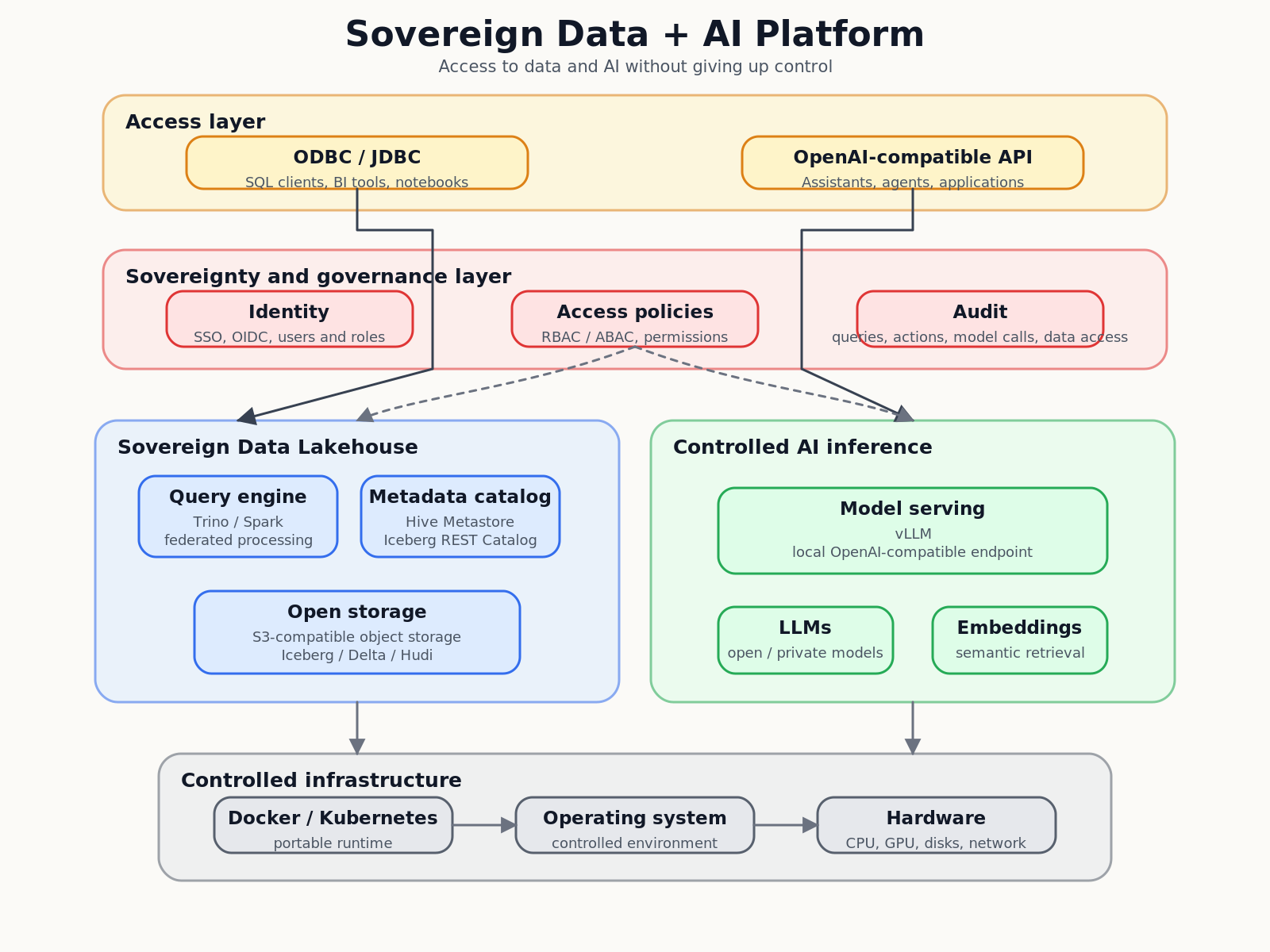
A sovereign architecture is not just about running services on-premises. It is about keeping data, metadata, identity, permissions, inference and auditability under conscious control.
The hard part is not deploying containers. The hard part is making the system coherent:
identity should be centralized;
permissions should follow the user;
data access should be auditable;
models should not bypass governance;
assistants should not invent answers;
generated artifacts should be traceable;
and the platform should remain portable.
This is where data architecture and AI architecture stop being separate disciplines.
What I will write about
This blog will be mainly technical, but not purely theoretical. The idea is to write from the trenches: what I am building, testing, debugging and learning.
Some of the topics I expect to cover:
Data sovereignty and architecture. What it means to design platforms that preserve control, portability and independence. Where on-premises makes sense, where cloud makes sense, and where hybrid models become unavoidable.
Data Lakehouse platforms. Storage, compute, metadata, federation, open formats, Kubernetes deployments, identity integration, observability and operational patterns.
AI assistants over data. TAG, Text-to-SQL, RAG, semantic search, SQL agents, tool calling, query validation, result grounding and conversational interfaces.
Agentic AI. ReAct-style loops, supervisors, worker agents, tool registries, traces, memory, routing, failure handling and the difference between a demo agent and a reliable system.
Evaluation. How to test assistants that interact with data. Benchmarks, difficulty levels, deterministic validation, qualitative metrics and why “it answered something plausible” is not good enough.
Security and governance. Authentication, authorization, guardrails, audit trails, tenant isolation, data permissions and the risks of connecting LLMs directly to enterprise data.
Open-source and local AI. Running models with vLLM, using open models, deploying inference services locally, embedding models, GPU constraints and the trade-offs between control and convenience.
And probably many unexpected things along the way.
Because every real project starts with a clean diagram and ends with logs, edge cases and uncomfortable questions.
The tone of this blog
This will not be a blog about hype.
AI is useful, but it is not magic. LLMs can reason surprisingly well in some contexts and fail absurdly in others. Agents can automate workflows, but they can also loop, hallucinate or call the wrong tool with total confidence. Data platforms can provide powerful abstractions, but they still depend on good engineering.
So the tone here will be pragmatic.
When something works, I will explain why I think it works. When something fails, I will try to understand the failure. When a design decision has trade-offs, I will make them explicit. When I am not sure, I will say so.
The objective is not to sell a perfect architecture. The objective is to learn in public.
A starting point
This blog starts from one conviction:
Organizations should be able to extract value from their data without losing control over it.
That requires more than technology. It requires architecture, governance, security, usability and a clear understanding of what AI can and cannot do.
But technology matters. Tools shape possibilities. If the only practical way to use AI over your data is to send everything to an external platform, then sovereignty becomes theoretical. If only technical experts can access information, then data-driven decision-making remains limited. If assistants cannot be audited, they cannot be trusted.
So the challenge is clear: build systems that make data easier to use while keeping it under control.
That is the ground this blog will cultivate.